Bayesian Orchestrator
Since March, I have been spending pretty much all my weekends doing… homework. Why? In March, I joined the AI Performance Engineering course at Nebius Academy, which also gave me the courage to try my own ideas and participate in the Nebius AI serverless challenge (and spend more weekends on that…). So here it goes!
There is a classic three-circle Venn diagram with cheap, fast, and good, where the intersection of these 3 bubbles is impossible. But how does one choose a possible combination depending on the task at hand, and whilst not being a trillionaire? Here, I address this problem in the context of LLM routing, and my motivation comes from a recent position paper on the need for Bayes in agentic AI orchestration.
It would be unreasonable to assume that an LLM can perform principled probabilistic reasoning (e.g. see this or this), and instead of trying to make LLMs more principled (which, in my very biased case, means more Bayesian), I built an external controller that tracks how reliable each model is and routes questions accordingly. The approach defines a hierarchical Bayesian reliability model to estimate the probability that each model will answer correctly, based on everything observed so far, that is the question type, subject matter, model identity, and picks the option with the best expected utility.
The utility function used here is rather simple but still balances accuracy against cost: utility = correctness − (cost scale × call cost), where one tunes the cost scale to express one’s preferences for increased costs versus accuracy.
Before you call a model, you can only use what you know ahead of time, which model it is, what subject the question is about, and how long the question is, which gives a pre-call probability estimate and determines which model to call first. After the model responds, the orchestrator gets more signals: how self-confident the model was, how long it took, and how many tokens it used. These go into a post-call probability estimate that determines whether the answer is given or the next model is called. If the first model’s answer looks doubtful, the orchestrator checks whether calling a second model is worth it. If the expected gain from a second call clears a threshold, it makes the call, then combines the answers using a Noisy-OR rule (which roughly says that if either model supports an answer, then that counts).
I test my idea on MMLU-Pro, a multiple-choice benchmark, with three models: two ~30B models and a 120B model, namely:
nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B
Qwen/Qwen3-30B-A3B-Instruct-2507
openai/gpt-oss-120b
For the setup, I ran it as a Nebius Serverless AI Job, which was a good fit because the workload is a finite batch evaluation: the container runs on CPU, model inference happens through APIs, every completed question-model call is checkpointed to persistent storage (meaning interrupted runs can continue without repeating paid calls).
The job samples 4000 MMLU-Pro questions, calls every configured model, checkpoints completed calls to persistent storage, fits Bayesian reliability models, and writes the final report, JSON summary, and plots. The repo is available on GitHub.
The results support the idea of Bayesian adaptive policy:
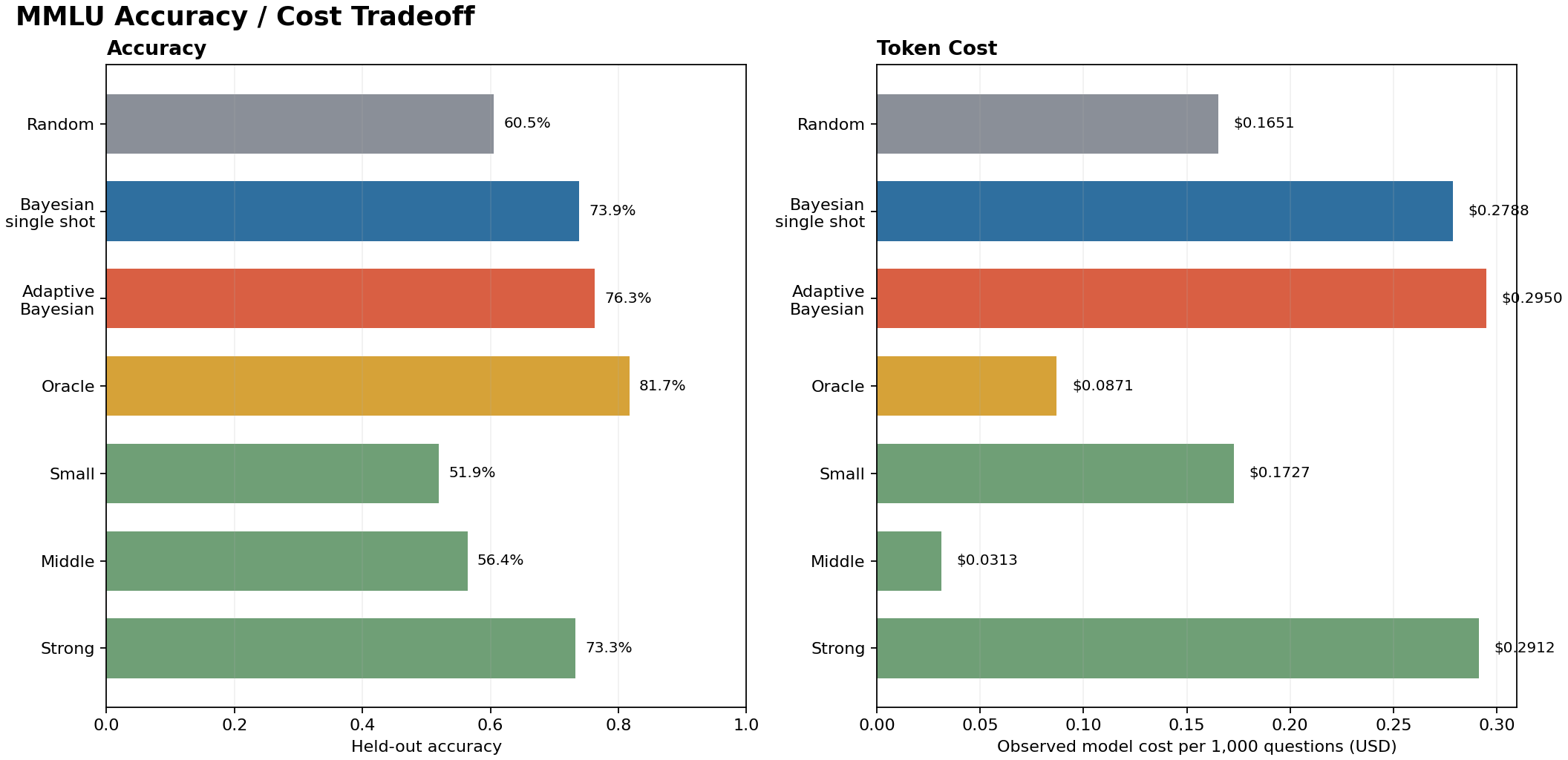
The adaptive policy called a second model on about one third of the questions. Compared to always using the big model, it’s more accurate but slightly more expensive; this could be tuned with the cost scale discussed above. The oracle looks cheap because it gets to retroactively pick the cheapest correct answer. In the real world, you don’t get to do that, so here I use the oracle as an upper bound.
LLMs themselves might be subtle predictors, but combined with Bayes-inspired reasoning, we can allocate resources more efficiently, manage costs and latencies, and adapt routing decisions as evidence accumulates. Workflows (Bayesian, please) over tools!
The project has gaps to fill, yet I feel good that I was able to build it up to its current state.
#NebiusServerlessChallenge
Originally published on Substack.